Performance Benchmarking on
Many-to-Many (M:N) Relationships
with Variations in Indexing and
Sizes of Object Databases
Performance Comparison with Multiple Query Conditions in an Object Hierarchy
The tests in the links below show RootDB and RQL performance on a simple query when compared to database queries using SQL on the traditional relational database MariaDB.
- Performance Comparison Many-to-Many (M:N) Relationships with Indexing
Benchmark for Query Command Languages RQL and SQL with Databases MariaDB and Xodus - Performance Comparison Many-to-Many (M:N) Relationships without Indexing
Benchmark for Query Command Languages RQL and SQL with Databases MariaDB and Xodus
RootDB and RQL make it very easy to write and execute sophisticated database queries on complex data structures, regardless of the relationships used in them.
On the other hand, traditional relational databases with SQL are very difficult and tedious, if not nearly impossible to use for advanced queries of complex data structures, because they have challenges with many entity relationships in both the expressive power and performance.
For this reason, the tests presented here are performed without any direct comparison to SQL database queries in the relational databases.
Object Model and Test Data for Performance Tests
The object model consists of 12 Java classes N1-N4, M1-M4 and S1-S4.
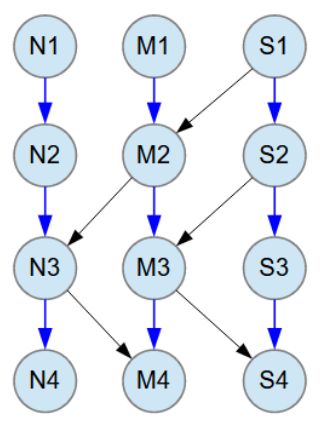
Blue arrow relationships between classes are M:N (many-to-many). All M:N relationships have 1-3 child objects at random.
Black arrow relationships between classes are M:1 (many-to-one).
Twelve object databases were created to evaluate how performance is affected by the number of objects and the extent of indexing coverage.
The tests are categorized into three groups based on database size, with object counts of 12 x 100K, 12 x 1M, and 12 x 2M (where K=Kilo, M=Million), as shown in the table below.
Each category applies four different levels of indexing: no indexing (none), indexing only the value field in each class (value fields), indexing only the relationships of each class (all relations), and the broadest scope, which includes indexing all relationships in addition to the value field (value fields, all relations).
| RootDB Object Databases on MariaDB | |||||
|---|---|---|---|---|---|
| Database Name | Number of Objects | Indexes | Creation Time (s) | Objects per Second | Database Size (GB) |
| ex100Knx | 12 x 100K | none | 87 | 13764 | 0,644 |
| ex100Kvx | 12 x 100K | value fields | 93 | 12940 | |
| ex100Krx | 12 x 100K | all relations | 1532 | 783 | |
| ex100Kvrx | 12 x 100K | value fields, all relations | 1614 | 744 | 0,872 |
| ex1Mnx | 12 x 1M | none | 856 | 14022 | 5,18 |
| ex1Mvx | 12 x 1M | value fields | 1016 | 11809 | |
| ex1Mrx | 12 x 1M | all relations | 16238 | 739 | |
| ex1Mvrx | 12 x 1M | value fields, all relations | 16304 | 736 | 7,06 |
| ex2Mnx | 12 x 2M | none | 1641 | 14622 | 10,3 |
| ex2Mvx | 12 x 2M | value fields | 2161 | 11101 | |
| ex2Mrx | 12 x 2M | all relations | 31889 | 753 | |
| ex2Mvrx | 12 x 2M | value fields, all relations | 32605 | 736 | 13,6 |
Processor = AMD Ryzen 7 3700X, Disk Samsung SSD 860 EVO M.2 1TB
Creating object databases without indexing (none) or with only single-field indexing (value fields) is highly efficient, allowing 11,000 to 14,000 objects to be written per second, regardless of database size.
Indexing all 14 relationships (with or without value fields) significantly reduces write speed, limiting it to just 736–783 objects per second. Given the extensive indexing coverage, this performance can still be considered good, or at least reasonable.
Indexing (value fields, all relations) increases the database size by roughly 30 percent, which is a relatively minor issue in today’s era of inexpensive disk storage, especially when compared to the more significant impact on write performance.
An especially positive aspect is that increasing the database size does not slow down object write operations, as the performance remains consistently stable regardless of the extent of indexing.
Naturally, indexing is implemented to enhance query performance, and its positive impact on them is substantial. The results demonstrating this improvement are presented below.
RQL Queries with Variations in Indexing and Object Database Sizes
12 Object Databases Tested in MariaDB
The search conditions used for performance testing of the object databases described above are shown in the image below.
In all tests, the same search conditions are used, which searches M1 class objects from the database. The red X marks indicate the classes N3, M4, and S4, where search conditions are applied to the value fields within the data structure of class M1. The paths from the root class M1 to the search condition classes are shown with red dashed lines.
The found M1 objects are returned as complete data structures, including all objects that are reachable from the M1 root class. This of course includes classes N3, M4, and S4, which have the value search conditions, but also objects from classes M2, M3, and N4, which are reachable from class M1. All reachable classes from class M1 are marked with blue X marks.
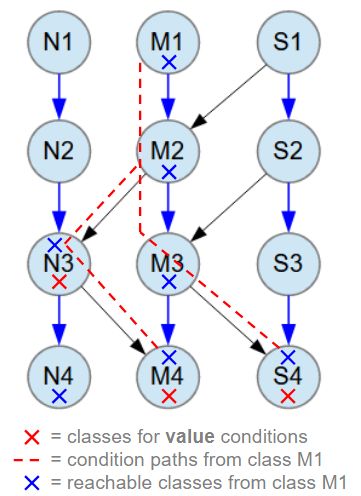
Blue arrow relationships between classes are M:N (many-to-many). All M:N relationships have 1-3 child objects at random.
Black arrow relationships between classes are M:1 (many-to-one).
The search conditons for the three value fields in classes N3 (value=976), S4 (value=50) and M4 (value=770) are represented as a RQL query expression below.
RQL query:
(m2.n3.value = 976, m2.m3.s4.value = 50, m2.n3.m4.value = 770)
The Java source code that executes the RQL query expression for the class M1 in the object database is shown below.
//Variable rdb is the opened RootDB object database.
//RootStore object is created for the M1 class.
RootStore r2 = rdb.getRootStore("fi.rootrql.ex100Knx.M1");
Query query = Query.createQuery()
.addQ1Query(r2,
"(m2.n3.value = 976," +
" m2.m3.s4.value = 50," +
" m2.n3.m4.value = 770"
+ ")");
List<M1> list = query.queryQ1Objects();
rdb.close();
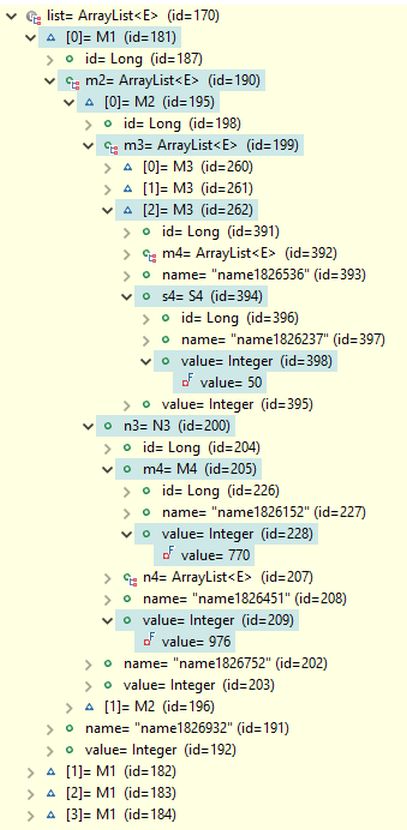
An example of query results is shown below, containing the complete data structures of the retrieved four M1 objects. Note that, for example, the expanded [0]=M2 object has a list of three M3 objects in its field m3 and only the expanded object [2]=M3 has the searched value 50 in its s4=S4 object. Thus, the lists may contain objects that do not match the search criteria, but are included in the results because the returned M1 objects contain their complete data structures.
Query Result Example: The four found M1 objects are returned in a list, with the first M1 object expanded to display the value fields where the search conditions were applied.
The twelve object databases with variations in indexing and object counts were all tested using the same query described above. The results categorized by database size and indexing strategy are presented in the table below.
| RootDB Object Databases on MariaDB | Execution Times / Seconds | |||||
|---|---|---|---|---|---|---|
| Database Name | Number of Objects | Indexes | Number of Found Objects | Total | Create Objects | Search |
| ex100Knx | 12 x 100K | none | 4 | 5,008 | 0,018 | 4,99 |
| ex100Kvx | 12 x 100K | value fields | 4 | 3,481 | 0,021 | 3,46 |
| ex100Krx | 12 x 100K | all relations | 4 | 1,676 | 0,016 | 1,66 |
| ex100Kvrx | 12 x 100K | value fields, all relations | 4 | 0,389 | 0,029 | 0,36 |
| ex1Mnx | 12 x 1M | none | 40 | 51,575 | 0,185 | 51,39 |
| ex1Mvx | 12 x 1M | value fields | 40 | 32,035 | 0,155 | 31,88 |
| ex1Mrx | 12 x 1M | all relations | 40 | 13,053 | 0,143 | 12,91 |
| ex1Mvrx | 12 x 1M | value fields, all relations | 40 | 4,972 | 0,132 | 4,84 |
| ex2Mnx | 12 x 2M | none | 80 | 147,921 | 0,321 | 147,60 |
| ex2Mvx | 12 x 2M | value fields | 80 | 76,107 | 0,347 | 75,76 |
| ex2Mrx | 12 x 2M | all relations | 80 | 27,756 | 0,276 | 27,48 |
| ex2Mvrx | 12 x 2M | value fields, all relations | 80 | 12,375 | 0,305 | 12,07 |
Processor = AMD Ryzen 7 3700X, Disk Samsung SSD 860 EVO M.2 1TB
The number of M1 objects found is 4 in the smallest databases with 12 x 100K objects. The number of objects found increases with the size of the database, so that a database with 12 x 2M objects has 80 matches for the query conditions.
The focus of the results is of course on execution times and their changes depending on the size of the database and the indexing used. Three execution times are shown, which are the search time of the query (Search), the creation time of found M1 objects (Create Objects), and the total time (Total) summing up these two times. The results show that the performance can be evaluated solely on the basis of the search time of the query (Search), since the object creation time (Create Objects) per result object seems to be approximately the same in all cases.
No Indexes (none)
Indexes are important for performance, but avoiding them can be even more important in large databases because they consume a significant amount of memory and maintaining them negatively affects database performance.
Today, very large SSDs and similar memories are affordable, so the downside of indexing is mainly the inefficiency of writing and maintaining data when indexing is widely used. This can also be seen in the table above, where the data write speed is 11000 - 14000 objects per second without indexing and only 735 - 783 objects with the most comprehensive indexing.
The good news with RootDB is that without any indexing, query execution times only increase roughly linearly as the database size increases, even if the query is run over multiple many-to-many relationships. This almost linearly increasing execution time guarantees that using the object databases is predictable and reliable without any indexing, even though the search times in large databases can grow considerably long, there is no need to fear that the query execution will freeze in them either. The complexity of the object model used in the database, the number of its relations, of course significantly affects the execution time, but even remarkably complex object models do not prevent RootDB from succeeding in its database queries, and this does not depend on how indexing is used or not used at all.
The query search times (Search) shown below are 4.99, 51.39, and 147.60 seconds with object counts of 12 x 100K, 12 x 1M, and 12 x 2M (where K=Kilo, M=Million), all of which are long for an interactive application, but otherwise reasonable since no indexing was used. Indexes can be left out and it is worth doing when the efficiency of data writing and maintaining needs to be maximized.
Although here is not prestented any test-based comparison with, for example, relational databases that use the SQL command language, it is quite certain that they are significantly less efficient without indexing. The required SQL command is challenging to write and even more difficult to write the SQL commands that return the result records to form the final result objects. They can even get stuck because multiple many-to-many relations without indexing are not suitable for relational databases and SQL, as shown in the tests in link SQL Query Using a Traditional Relational Database Schema in MariaDB. At the same time, this is a good example of the superiority of the RQL query language over SQL, which of course is also completely self-evident, because SQL does not offer any support for retrieving objects.
Indexes of Value Fields (value fields)
An effective way to improve database query speed is to use indexing for all value fields in the database's object model. However, not all value fields in the database can typically be indexed, as doing so may result in excessive memory consumption and significantly slow down data writing and maintenance due to the overhead of managing multiple indexes. Fortunately, it's often possible to identify the value fields required for queries during the database design phase and restrict indexing to those fields only.
In the results above, indexing value fields clearly improves search times, and the relative improvement increases as the database size increases. This is completely natural, because direct access to the searched value with the help of an index obviously offers a greater advantage over the sequential search that the database would otherwise have to perform. In the smallest database (12 x 100K) with indexing, the query time 3,46 seconds is 69 percent compared to the query without indexing. In the largest database (12 x 2M), the query time 75,76 seconds has improved to 51 percent of the query without indexing. However, both query times are still quite long and would probably not meet the performance requirements of an interactive application.
Indexes of All Relations (all relations)
Above, indexing value fields actually provided a fairly modest improvement in database query times compared to the query without indexing. This is because most of the query time is spent resolving relationships between objects.
The effect of relations on the performance of database searches can be studied by indexing all relations in the database, the results of which are also shown in the table above. The results show that relations have a much greater impact on performance than searching of the value fields. In the smallest database (12 x 100K) with indexing, the query time 1,66 seconds is 33 percent compared to the query without indexing. In the largest database (12 x 2M), the query time 27,48 seconds has improved to 19 percent of the query without indexing. These can already be considered almost acceptable search times even in interactive applications.
Indexes of Value Fields and All Relations (value fields, all relations)
Based on the examples described above, it can be easily concluded that the best performance of database queries is obtained when both value fields and relations are indexed. This ensures that all data required for a query is accessed as efficiently as modern databases allow.
The results demonstrate significantly better performance compared to the alternatives discussed earlier, and extensive indexing has about the same performance cost in data writing and maintenance as indexing only all relations. This is of course due to the fact that indexing one value field per class is small and quick compared to the indexing of all relations. However, if several value fields per object class were needed in a database search, indexing these fields would reduce the performance of writing objects to the database in proportion to their number.
The results are compelling and show consistently excellent performance across databases of all sizes, from the smallest to the largest:
- In the smallest database (12 x 100K), the query time 0,36 seconds is 7 percent compared to the query without indexing.
- In the middle size database (12 x 1M), the query time 4,84 seconds is 9 percent compared to the query without indexing.
- In the largest database (12 x 2M), the query time 12,07 seconds is 8 percent compared to the query without indexing.
With extensive indexing, query performance can be deemed excellent and is sufficient even for interactive applications, provided that acceptable execution times are scaled according to the database size. Execution time increases almost linearly with the number of objects, a characteristic highly valued by database developers. The results are objects of class M1, containing their full data structures, including all objects reachable from the M1 objects. This is a feature that is difficult to achieve with traditional relational databases and the SQL command language.
Summary
A database search has been presented, in which search criteria are set at different levels in the hierarchy of the data structure and the result is objects that contain their complete data structures. This kind of freedom to set search criteria for any data structure with a complex hierarchy is not available in other database systems. If attempted on them, the end result would likely be something very complex, only partially functional, and poor performance (compare for example Hibernate).
Tests on 12 different databases reveal that database size and extent of indexing are the most important factors affecting the performance of RootDB/RQL databases. These two factors are interdependent because the size of the database directly affects the choice of indexing. The way the database is used also has an effect, because in interactive applications a clearly better performance of database searches is required than, for example, in applications based on batch runs.
No Indexes (none)
Without any indexing (none), query execution times only increase roughly linearly as the database size increases, even if the query is run over multiple many-to-many relationships. In addition, the best performance for writing data to the database is achieved, as time-consuming index maintenance is completely avoided. One of the main goals of RootDB has been to create a database system that can be used reliably and efficiently without indexing, regardless of the complexity of the data structures to be stored and the size of the database. RootDB succeeds quite well in this, so it is worth using it even without indexing.
When only one or a few fields are indexed, the drawbacks of indexing, such as slower data writing, are almost completely avoided. Carefully selecting value fields for indexing that are essential for database searches significantly improves query times, but non-indexed relationships between objects can still greatly diminish performance.
Indexes of Value Fields and All Relations (value fields, all relations)
RootDB provides the @Index annotation, which is a simple and powerful way to define any object model reference field (single or list field) to be indexed in the database. Indexing reference fields for many-to-many or one-to-many relationships is implemented with a completely new and unique method exclusive to RootDB. It is almost as efficient (only about 20% difference) as indexing of the many-to-one relationship for a single reference field. Many-to-many relationships have long been a major challenge in relational databases, making any significant improvement in their handling during queries a highly anticipated breakthrough.
Below is an example of Java source code where indexing is defined using RootDB's @Index annotation for the fields value, m3, and n3 in the M2 class of the object model. The value field is of integer data type. The m3 field is a list of references to M3 objects, representing a many-to-many relationship between M2 and M3. The n3 field is a reference to an N3 object, implementing a many-to-one relationship between M2 and N3.
package fi.rootrql.ex9wvrx;
import java.util.List;
import fi.rootrql.rql.clazz.Index;
@Index(name = "index1", fields = { "value" }, unique = false)
@Index(name = "index2", fields = { "m3" }, unique = false)
@Index(name = "index3", fields = { "n3" }, unique = false)
public class M2 {
public Long id;
public String name;
public Integer value;
public List<M3> m3;
public N3 n3;
public M2() {
super();
}
}
Indexing selected value fields based on their expected query usage, along with all relationships between objects, delivers the best possible query performance. The execution time of the same database queries is only 10-15 percent compared to results of indexing only the value fields needed in the search. Indexing the relationships between objects appears to be crucial for database search performance, especially when dealing with complex data structures.
Indexes of All Relations (all relations)
The test results from indexing value fields and relationships (value fields, all relations) suggest it may be more advantageous to focus solely on indexing the relationships between objects. This approach was also tested, and the results are promising, with performance improving as the database size grows - indicating that a larger number of objects is not detrimental, but rather beneficial, as relative performance improves. For instance, with the smallest database (12 x 100K), the execution time for the same search is reduced to 48% compared to indexing only the value fields. On the largest database (12 x 2M), the search time improves further to 36%, demonstrating that as the number of objects increases, relative performance actually improves.
Conclusions
Twelve object databases were created to evaluate the impact of object count and indexing strategy on performance. The object model used to construct the data structures included nine many-to-many and five many-to-one relationships. In this complex hierarchical model, a database search was designed with search criteria applied at three different levels. Execution times were measured across databases of 12 x 100K, 12 x 1M, and 12 x 2M objects to assess the effect of database size. Additionally, the impact of various indexing strategies was evaluated using four approaches: no indexing (none), indexing value fields (value fields), indexing all relationships (all relations), and indexing both value fields and all relationships (value fields, all relations).
The following observations and conclusions were made about the operation of the RootDB database and its query language RQL.
Object Write Speed During Database Creation
- Creating object databases without indexing (none) or with only single-field indexing (value fields) is highly efficient, allowing 11,000 to 14,000 objects to be written per second, regardless of database size.
- Indexing all relationships (all relations) or both value fields and all relationships (value fields, all relations) significantly degrades performance, resulting in a write rate of only 700 to 800 objects per second, regardless of database size.
- An important conclusion is that the write speed remains relatively constant, regardless of database size.
Databases Without Indexing (none)
- RootDB and RQL are designed to operate efficiently and predictably even without indexing.
- Ideal for storing and managing large volumes of data, as the object write speed achieves its maximum without indexing.
- Query execution times are predictable, increasing approximately linearly with database size, even when queries involve multiple many-to-many relationships.
- A search result is always guaranteed, though it may take longer without indexing. Database searches never fail to complete.
Extensive Indexing Provides the Best Query Performance (value fields, all relations)
- The best query performance is achieved when indexing is comprehensive, covering all value fields of object classes used in searches, along with all object relationships.
- Query execution times are excellent and predictable, increasing approximately linearly with database size, even when queries involve multiple many-to-many relationships.
- Query execution times are suitable for interactive applications, as long as performance expectations are aligned with the database size.
- Object write performance is reduced by the overhead of indexing both value fields and object relationships. The write speed (objects per second) remains relatively constant, regardless of the number of objects or database size - an important feature that enables the use of even very large databases.
Indexing Only Object Relations is a Tempting Option (all relations)
- Indexing only object relationships introduces a completely new approach to database indexing. Traditionally, relational databases have also indexed relationship tables, but the primary focus has been on indexing table columns and their combinations to optimize search efficiency.
- RootDB offers the option to skip indexing object value fields entirely, as indexing object relationships alone delivers strong performance for all database searches.
- This allows value fields to be freely used in queries without compromising speed. The performance remains robust, with queries taking only 2 to 3 times longer compared to extensive indexing that includes value fields.
- If a database contains many value fields needed for searches, it may be tempting to exclude them from indexing to avoid the negative impact on data write performance.
- Indexing only object relationships presents an intriguing concept for database programmers, as it completely eliminates the need to plan and implement indexing for value fields. This approach also avoids the need for future adjustments when database search optimization becomes necessary.
The most significant challenges in databases have been related to performance issues in data writing, maintenance, and search efficiency. These problems have largely stemmed from the number and complexity of data relationships, with many-to-many relationships being particularly problematic. RootDB and RQL address these traditional limitations of relational databases while offering a higher-level conceptual framework for database functionality. Notably, RootDB excels at handling complex data models, allowing hierarchical structures and many-to-many relationships to be managed using the same object-oriented programming principles. Performance testing on 12 different databases demonstrated that, depending on the indexing strategy, the system delivers good to excellent results. Moreover, performance is always predictable and reliable, ensuring consistent query results regardless of the database size or search complexity.
Comparing other database products, such as relational databases like MariaDB, Oracle, SQL Server, and PostgreSQL, to the results from the 12 databases presented above is challenging. Implementing the small hierarchical data structure in these systems requires significant effort, and performing similar database searches is either very difficult or nearly impossible, especially when the required results are M1 objects with their complete data structures. While relational databases weren’t originally designed for object-oriented use, the world has evolved, and objects are now central to modern programming. It seems almost unreasonable that much of today’s data management still depends on more than 50 years old concepts and methods.
Performance Outlook
The tests described above were conducted on five-year-old hardware, consisting of a legacy processor and SSD. Modern multi-core processors and SSDs, however, have the potential to reduce RootDB/RQL execution times by more than tenfold. To investigate this potential, the same benchmark tests were subsequently conducted on a new system equipped with an AMD Ryzen 9 9950X 16-Core Processor (4.30 GHz), 32 GB of memory, and a Samsung SSD 990 PRO 2TB with an M.2 PCIe 4.0 x4 interface and NVMe 2.0 protocol.
The most significant improvement in the new configuration is the processor, which features double the core count, enabling 32 threads to execute concurrently. While simply doubling the number of processor cores alone does not guarantee a tenfold performance increase, the results indicate a substantial improvement, demonstrating that all available processor capacity is effectively utilized. The results of these updated benchmarks are presented in the table below.
| RootDB Object Databases in MariaDB | Execution Times / Seconds | ||||||
|---|---|---|---|---|---|---|---|
| Database Name | Number of Objects | Indexes | Found M1 Objects | Total | Create Objects | Search | Search Improvement Coefficient |
| ex100Knx | 12 x 100K | none | 4 | 2,624 | 0,0230 | 2,601 | 1,92 |
| ex100Kvx | 12 x 100K | value fields | 4 | 1,825 | 0,0231 | 1,802 | 1,92 |
| ex100Krx | 12 x 100K | all relations | 4 | 0,619 | 0,008 | 0,611 | 2,72 |
| ex100Kvrx | 12 x 100K | value fields, all relations | 4 | 0,291 | 0,023 | 0,268 | 1,34 |
| ex1Mnx | 12 x 1M | none | 40 | 13,522 | 0,176 | 13,346 | 3,85 |
| ex1Mvx | 12 x 1M | value fields | 40 | 9,878 | 0,1716 | 9,706 | 3,28 |
| ex1Mrx | 12 x 1M | all relations | 40 | 7.142 | 0,1678 | 6,974 | 1,85 |
| ex1Mvrx | 12 x 1M | value fields, all relations | 40 | 2,321 | 0,173 | 2,148 | 2,25 |
| ex2Mnx | 12 x 2M | none | 80 | 28,13 | 0,35 | 27,78 | 5,31 |
| ex2Mvx | 12 x 2M | value fields | 80 | 18,939 | 0,355 | 18,584 | 4,08 |
| ex2Mrx | 12 x 2M | all relations | 80 | 15,09 | 0,3288 | 14,761 | 1,86 |
| ex2Mvrx | 12 x 2M | value fields, all relations | 80 | 4,479 | 0,3301 | 4,149 | 2,91 |
Processor = AMD Ryzen 9 9950X, Disk = Samsung SSD 990 PRO 2TB
The test results show query search time improvements ranging from 1.34x to 5.31x. Notably, 7 out of the 12 tests achieve more than a twofold improvement, surpassing the expected gains attributed solely to the doubling of processor cores. Even without indexing (none), the search times - 2.601, 13.346, and 27.78 seconds for database sizes of 12 x 100K, 12 x 1M, and 12 x 2M, respectively - are acceptable for many applications. Databases without indexing benefit from a reduced overall size and achieve an impressive write speed of nearly 24,000 objects per second, effectively utilizing the increased processor capacity.
Links to other pages on this site.
- Performance Benchmarking on Many-to-Many (M:N) Relationships with Variations in Indexing and Sizes of Object Databases: Performance Comparison: MySQL vs. MariaDB
- Performance Benchmarking on Many-to-Many (M:N) Relationships with Variations in Indexing and Sizes of Object Databases: Performance Comparison: PostgreSQL vs. MariaDB
- Performance Benchmarking on Queries of a New Category with Variations in Indexing and Object Database Sizes
Performance Comparison with Multiple Query Conditions in an Object Hierarchy - Performance Comparison Many-to-Many (M:N) Relationships with Indexing
- Performance Comparison Many-to-Many (M:N) Relationships without Indexing
- RootDB, Technical Features
- RootDB and RQL, Home
Page content © 2025

Contact us:
