Performance Benchmarking of
MySQL 9.1.0
Using a Java Object Model
Testing a Hierarchical Object Model with M:N Relationships,
Multiple Indexing Strategies, and Varying Database Sizes
This performance test evaluates MySQL version 9.1.0 as the storage platform for the latest version of the RootDB object database, tested on May 20, 2025. The test procedures are identical to those previously conducted with earlier versions of MySQL and MariaDB, as documented in link. However, note that the test computer has been upgraded: system memory has been increased from 16 GB to 32 GB, and the SATA-based SSD has been replaced with a significantly faster M.2 NVMe drive. The current performance of this upgraded storage device is demonstrated in the disk test results below.
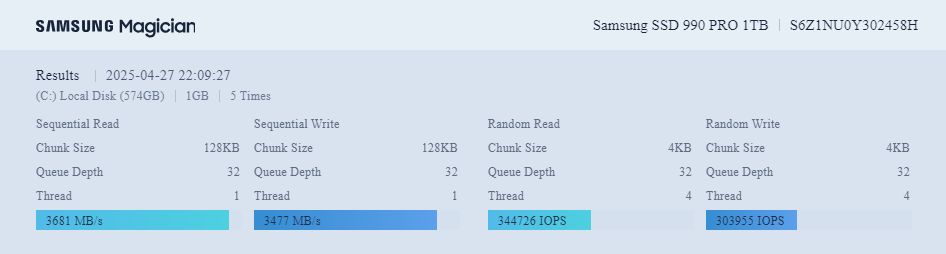
Performance evaluations are repeated here due to the hardware upgrades described above, improvements in RootDB’s internal algorithms, and the availability of a new version of the MySQL database product. Developments in both RootDB and MySQL may introduce changes that significantly affect performance. In particular, enhancements in indexing mechanisms, concurrency control, and transaction processing in MySQL can have a substantial impact on RootDB performance.
The object model and the characteristics of the created test databases, including various indexing strategies and sizes, are described in the following section.
Object Model and Test Data for Performance Tests
The object model consists of 12 Java classes N1-N4, M1-M4 and S1-S4.
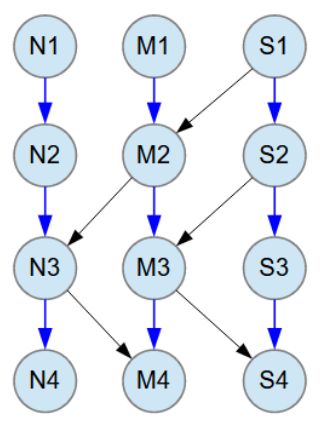
Blue arrow relationships between classes are M:N (many-to-many). All M:N relationships have 1-3 child objects at random.
Black arrow relationships between classes are M:1 (many-to-one).
Twelve object databases were created to evaluate how performance is affected by the number of objects and the extent of indexing coverage.
The tests are categorized into three groups based on database size, with object counts of 12 x 100K, 12 x 1M, and 12 x 2M (where K=Kilo, M=Million), as shown in the table below.
Each category applies four different levels of indexing: no indexing (none), indexing only the value field in each class (value fields), indexing only the relationships of each class (all relations), and the broadest scope, which includes indexing all relationships in addition to the value field (value fields, all relations).
| RootDB Object Databases on MySQL | |||||||
|---|---|---|---|---|---|---|---|
| Database Name | Number of Objects | Indexes | Creation Time (s), CT | Objects per Second | Database Size (GB) | ||
| ex100Knx | 12 x 100K | none | 140,77 | 8524 | 0,52 | ||
| ex100Kvx | 12 x 100K | value fields | 171,18 | 7010 | |||
| ex100Krx | 12 x 100K | all relations | 343,38 | 3495 | |||
| ex100Kvrx | 12 x 100K | value fields, all relations | 355,46 | 3376 | 0,71 | ||
| ex1Mnx | 12 x 1M | none | 1406,92 | 8529 | 5,1 | ||
| ex1Mvx | 12 x 1M | value fields | 2141,61 | 5603 | |||
| ex1Mrx | 12 x 1M | all relations | 3234,51 | 3710 | |||
| ex1Mvrx | 12 x 1M | value fields, all relations | 4176,52 | 2873 | 6,9 | ||
| ex2Mnx | 12 x 2M | none | 2794,42 | 8589 | 10,3 | ||
| ex2Mvx | 12 x 2M | value fields | 4583,51 | 5236 | |||
| ex2Mrx | 12 x 2M | all relations | 6205,50 | 3868 | |||
| ex2Mvrx | 12 x 2M | value fields, all relations | 8741,75 | 2745 | 13,6 | ||
Processor = AMD Ryzen 7 3700X, Memory 32GB, Disk Samsung SSD 990 PRO M.2 NVMe 1TB
Creating object databases without indexing (none) or with only single-field indexing (value fields) on value fields is moderately efficient in MySQL 9.1.0, achieving write rates between 5,603 and 8,589 objects per second, independent of database size. The ability to maintain consistent throughput as the database grows supports stable and reliable performance, even with large data volumes.
Indexing all 14 relationships (with or without value fields) significantly reduces write performance in MySQL 9.1.0, limiting throughput to 2,745–3,868 objects per second. Despite this reduction, the throughput remains at approximately half the level achieved without indexing, which can be considered a reasonably good result, as indexing is known to be a performance-intensive task for databases.
The excerpt below from Task Manager shows system behavior during concurrent writing by 20 threads using the most extensive indexing configuration (value fields, all relations). During this operation, CPU utilization reaches approximately 99%, and SSD load remains relatively high at around 60%. This suggests that write performance is somewhat limited by CPU processing but also increasingly affected by disk throughput. The 60% SSD load indicates a substantial I/O demand, implying that indexing operations in MySQL may contribute significantly to overall performance under heavy write conditions.

While MySQL provides reliable indexing capabilities through its InnoDB storage engine, the results of this test indicate that write performance under multithreaded workloads is constrained not only by CPU capacity but also by substantial disk load. The observed I/O intensity suggests that the indexing algorithms may not be fully optimized for high concurrency and write intensive scenarios. Although MySQL's indexing performs reasonably well, there remains considerable room for improvement in indexing efficiency, especially when compared to PostgreSQL and certain commercial database systems.
A positive result is that increasing the database size does not degrade object write performance. Write speed remains consistently stable, regardless of both database size and the extent of indexing.
The size of MySQL databases increases by slightly more than 30 percent when using the most extensive indexing configuration (value fields, all relations). For example, the largest database without indexing occupies 10.3 GB, while the fully indexed version increases the size by about 32 percent, consuming 13.6 GB. This suggests that MySQL allocates a substantial amount of storage for indexing, which has a significant impact on the overall space requirements.
The results above show that MySQL delivers moderate performance in write operations when indexing is not used, with throughput ranging from 5,603 to 8,589 objects per second. When indexing is applied, throughput decreases to 2,745–3,868 objects per second, which may indicate limitations in indexing efficiency under multithreaded workloads. Disk space consumption remains reasonable, as the most extensive indexing configuration (value fields, all relations) increases storage requirements by only about 32 percent. This is a clear advantage, since indexing plays a critical role in improving query execution speed, and its effectiveness is far more important than the additional storage it requires.
RQL Queries with Variations in Indexing and Object Database Sizes
12 Object Databases Tested on MySQL
The search conditions used for performance testing of the object databases described above are shown in the image below.
In all tests, the same search conditions are used, which searches M1 class objects from the database. The red X marks indicate the classes N3, M4, and S4, where search conditions are applied to the value fields within the data structure of class M1. The paths from the root class M1 to the search condition classes are shown with red dashed lines.
The found M1 objects are returned as complete data structures, including all objects that are reachable from the M1 root class. This of course includes classes N3, M4, and S4, which have the value search conditions, but also objects from classes M2, M3, and N4, which are reachable from class M1. All reachable classes from class M1 are marked with blue X marks.
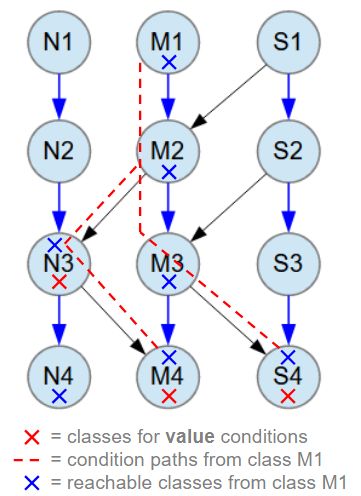
Blue arrow relationships between classes are M:N (many-to-many). All M:N relationships have 1-3 child objects at random.
Black arrow relationships between classes are M:1 (many-to-one).
The search conditons for the three value fields in classes N3 (value=976), S4 (value=50) and M4 (value=770) are represented as a RQL query expression below.
RQL query:
(m2.n3.value = 976, m2.m3.s4.value = 50, m2.n3.m4.value = 770)
The Java source code that executes the RQL query expression for the class M1 in the object database is shown below.
//Variable rdb is the opened RootDB object database.
//RootStore object is created for the M1 class.
RootStore r2 = rdb.getRootStore("fi.rootrql.ex100Knx.M1");
Query query = Query.createQuery()
.addQ1Query(r2,
"(m2.n3.value = 976," +
" m2.m3.s4.value = 50," +
" m2.n3.m4.value = 770"
+ ")");
List<M1> list = query.queryQ1Objects();
rdb.close();
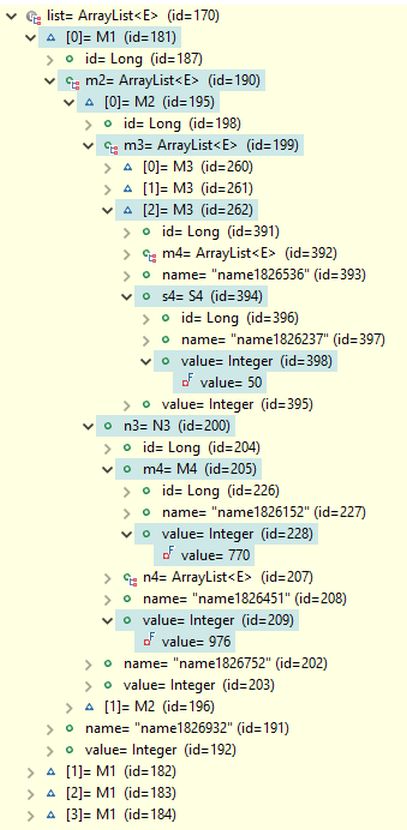
An example of query results is shown below, containing the complete data structures of the retrieved four M1 objects. Note that, for example, the expanded [0]=M2 object has a list of three M3 objects in its field m3 and only the expanded object [2]=M3 has the searched value 50 in its s4=S4 object. Thus, the lists may contain objects that do not match the search criteria, but are included in the results because the returned M1 objects contain their complete data structures.
Query Result Example: The four found M1 objects are returned in a list, with the first M1 object expanded to display the value fields where the search conditions were applied.
The twelve object databases with variations in indexing and object counts were all tested using the same query described above. The results categorized by database size and indexing strategy are presented in the table below.
Cold Cache Test Scenario
Many database systems can accelerate subsequent searches if the same, or even partially overlapping, data has already been retrieved during a previous query. Therefore, the results shown below represent a cold start scenario, where the database service has just been restarted and no prior data is cached. In other words, from a database performance standpoint, the search results are expected to reflect the longest possible execution times.
| RootDB Object Databases on MySQL, Cold Cache |
Execution Times / Seconds | ||||||
|---|---|---|---|---|---|---|---|
| Database Name | Number of Objects | Indexes | Number of Found Objects | Total | Create Objects | Search | |
| ex100Knx | 12 x 100K | none | 4 | 7,057 | 0,052 | 7,005 | |
| ex100Kvx | 12 x 100K | value fields | 4 | 5,044 | 0,047 | 4,997 | |
| ex100Krx | 12 x 100K | all relations | 4 | 1,629 | 0,010 | 1,619 | |
| ex100Kvrx | 12 x 100K | value fields, all relations | 4 | 0,736 | 0,052 | 0,684 | |
| ex1Mnx | 12 x 1M | none | 40 | 53,561 | 0,278 | 53,283 | |
| ex1Mvx | 12 x 1M | value fields | 40 | 40,837 | 0,307 | 40,530 | |
| ex1Mrx | 12 x 1M | all relations | 40 | 19,176 | 0,237 | 18,939 | |
| ex1Mvrx | 12 x 1M | value fields, all relations | 40 | 5,550 | 0,290 | 5,260 | |
| ex2Mnx | 12 x 2M | none | 80 | 106,837 | 0,542 | 106,295 | |
| ex2Mvx | 12 x 2M | value fields | 80 | 79,185 | 0,572 | 78,613 | |
| ex2Mrx | 12 x 2M | all relations | 80 | 37,903 | 0,547 | 37,356 | |
| ex2Mvrx | 12 x 2M | value fields, all relations | 80 | 10,482 | 0,538 | 9,944 | |
Processor = AMD Ryzen 7 3700X, Memory 32GB, Disk Samsung SSD 990 PRO M.2 NVMe 1TB
The number of M1 objects found is 4 in the smallest databases with 12 x 100K objects. The number of objects found increases with the size of the database, so that a database with 12 x 2M objects has 80 matches for the query conditions.
The focus of the results is of course on execution times and their changes depending on the size of the database and the indexing used. Three execution times are shown, which are the search time of the query (Search), the creation time of found M1 objects (Create Objects), and the total time (Total) summing up these two times. The results show that the performance can be evaluated solely on the basis of the search time of the query (Search), since the object creation time (Create Objects) per result object seems to be approximately the same in all cases.
No Indexes (none)
The query execution times (Search) are 7.005, 53.283, and 106.295 seconds for databases containing 12 × 100K, 12 × 1M, and 12 × 2M objects respectively (where K = thousand, M = million). Although these durations are long for interactive applications, they are good, possibly even very good, considering that no indexing was used. In scenarios where the primary objective is to maximize data insertion efficiency and minimize overhead, leaving indexes out is not only acceptable but can also be advantageous.
A notable strength of RootDB is its ability to maintain linear query execution time growth relative to database size, even without indexing and when traversing complex many-to-many relationships. This linear scaling behavior ensures that query performance remains predictable and reliable, even with very large databases. Although search times can become lengthy, there is no risk of query execution freezing or crashing.
Naturally, the complexity of the object model and the number of relationships have a significant impact on execution time. However, even with highly complex structures, RootDB is capable of successfully executing queries, regardless of whether indexing is used.
Indexes of Value Fields (value fields)
An effective way to improve database query performance is to apply indexing to all value fields in the object model. However, indexing every value field is not always feasible, as it can significantly slow down data insertion and maintenance due to the overhead of managing multiple indexes and increased memory consumption. Fortunately, it is often possible to identify the most frequently queried fields during the database design phase and limit indexing to those fields only.
The query execution times (Search) are 4.997, 40.530, and 78.613 seconds for databases containing 12 × 100K, 12 × 1M, and 12 × 2M objects, respectively (where K = thousand, M = million). Indexing only the value fields is sufficient to substantially improve query performance, reducing execution times to approximately 25 to 30 percent of those observed in the unindexed case. This gain in query speed comes with a tradeoff in write throughput, which decreases, for example, from 8,529 to 5,603 objects per second with 12 × 1M objects, representing an approximately 35 percent reduction. However, write performance remains consistent as the database size doubles to 12 × 2M objects, and the overall result can be considered at least reasonably good.
Indexes of All Relations (all relations)
Indexing all relationships improves query performance more effectively than indexing only the value fields. For smaller databases, the improvement is approximately 75 percent, decreasing to around 65 percent as the database size increases, when compared to the unindexed case.
The query execution times are 1.619, 18.939, and 37.356 seconds for databases containing 12 × 100K, 12 × 1M, and 12 × 2M objects, respectively (where K = thousand, M = million). These times increase approximately linearly with the size of the database, which is a very good result. However, this improvement in query speed comes with a reduction in write throughput, which drops below 4,000 objects per second. This represents a notable decrease in write performance compared to the case where only value fields are indexed.
Indexes of Value Fields and All Relations (value fields, all relations)
The best overall database search performance is naturally achieved when both value fields and all relationships are indexed. The query execution times (Search) are 0.684, 5.260, and 9.944 seconds for databases containing 12 × 100K, 12 × 1M, and 12 × 2M objects respectively (where K = thousand, M = million). As with all other query configurations, execution time increases approximately linearly with the growth of the database size.
When evaluating the quality of these query results, execution times should be considered in relation to the size of the database involved. A query time of 9.944 seconds may seem long for an interactive application, but when scaled to a database containing 24 million objects with multiple many to many relationships, it can be considered acceptable or even very good. At the other end, a query time well under one second with 1.2 million objects is more than sufficient for interactive use.
It is also worth emphasizing that the query results consist of complete objects of class M1. Each retrieved M1 object includes its entire data structure, containing all objects that are reachable from the M1 root. This level of completeness is a native feature of object databases and is difficult to replicate using traditional relational databases and the SQL language, where achieving similar results typically requires complex and costly programming effort.
Warm Cache Test Scenario
When a query is executed for the first time, the database engine must:
-
Read data blocks from disk into memory,
-
Possibly parse and optimize the query,
-
Execute the query by scanning or using indexes,
-
And build a result set.
On subsequent executions, if the same data pages are still in the buffer pool (i.e., cached in memory), the system can:
-
Bypass disk I/O entirely for those blocks,
-
Access data directly from memory,
-
Possibly reuse compiled query plans or intermediate results.
The situation described above, where the same database search is executed again immediately, represents a warm cache test scenario. In such cases, it is very likely that execution times will improve significantly compared to the initial run, because data and index pages remain in memory. The table below presents the results of the previous cold cache tests when the same queries are re-executed, and therefore reflect execution times in a warm cache situation. Distinguishing between cold and warm cache performance is essential in benchmarking, as it reveals how well the database behaves both in first-time access scenarios and in repeated or steady-state workloads.
| RootDB Object Databases on MySQL, Warm Cache |
Execution Times / Seconds | ||||||
|---|---|---|---|---|---|---|---|
| Database Name | Number of Objects | Indexes | Number of Found Objects | Total | Create Objects | Search | |
| ex100Knx | 12 x 100K | none | 4 | 6,039 | 0,046 | 5,993 | |
| ex100Kvx | 12 x 100K | value fields | 4 | 4,263 | 0,047 | 4,216 | |
| ex100Krx | 12 x 100K | all relations | 4 | 1,341 | 0,009 | 1,332 | |
| ex100Kvrx | 12 x 100K | value fields, all relations | 4 | 0,469 | 0,038 | 0,431 | |
| ex1Mnx | 12 x 1M | none | 40 | 42,295 | 0,272 | 42,023 | |
| ex1Mvx | 12 x 1M | value fields | 40 | 29,551 | 0,273 | 29,278 | |
| ex1Mrx | 12 x 1M | all relations | 40 | 14,104 | 0,234 | 13,870 | |
| ex1Mvrx | 12 x 1M | value fields, all relations | 40 | 3,166 | 0,250 | 2,916 | |
| ex2Mnx | 12 x 2M | none | 80 | 84,361 | 0,497 | 83,864 | |
| ex2Mvx | 12 x 2M | value fields | 80 | 57,754 | 0,510 | 57,244 | |
| ex2Mrx | 12 x 2M | all relations | 80 | 27,697 | 0,551 | 27,146 | |
| ex2Mvrx | 12 x 2M | value fields, all relations | 80 | 6,106 | 0,536 | 5,570 | |
Processor = AMD Ryzen 7 3700X, Memory 32GB, Disk Samsung SSD 990 PRO M.2 NVMe 1TB
When comparing warm and cold cache results, query performance improves significantly across all indexing strategies and database sizes. The beneficial effect of warm caching is slightly more pronounced with larger databases. Below, the impact of warm cache conditions on query execution times is briefly reviewed for each of the four indexing strategies.
No Indexes (none)
The query execution times are 85.55 percent, 78.87 percent, and 78.90 percent of the corresponding cold cache times for databases containing 12 × 100K, 12 × 1M, and 12 × 2M objects, respectively (where K = thousand, M = million). As the database size increases, the relative benefit of warm cache becomes more pronounced. However, the improvement from 85.55 percent to 78.87 percent appears to represent the practical performance limit in this configuration, as the result for the 12 × 2M database is nearly identical.
As is typical for RootDB, the execution time increases linearly with the size of the database. This is clearly demonstrated by the ratio of the query times for the 12 × 1M and 12 × 2M databases, which is almost exactly two to one, matching the relative sizes of the databases.
Indexes of Value Fields (value fields)
The query execution times are 84.37 percent, 72.24 percent, and 72.82 percent of the corresponding cold cache times for databases containing 12 × 100K, 12 × 1M, and 12 × 2M objects, respectively (where K = thousand, M = million). As the database size increases, the relative benefit of warm cache becomes approximately 5 percent more pronounced than in the configuration without indexing, described above. However, the transition from 12 × 1M to 12 × 2M objects does not yield further improvement, as the performance remains nearly unchanged between them.
Indexes of All Relations (all relations)
The query execution times are 82.27 percent, 73.24 percent, and 72.67 percent of the corresponding cold cache times for databases containing 12 × 100K, 12 × 1M, and 12 × 2M objects, respectively (where K = thousand, M = million). As the database size increases, the relative benefit of warm cache remains closely aligned with the results observed when indexing only the value fields (value fields).
Indexes of Value Fields and All Relations (value fields, all relations)
The query execution times are 63.01 percent, 55.44 percent, and 56.01 percent of the corresponding cold cache times for databases containing 12 × 100K, 12 × 1M, and 12 × 2M objects, respectively (where K = thousand, M = million). Indexing both value fields and all relationships yields the greatest benefit from warm cache conditions, with query times reduced by approximately 37 to 45 percent. Once again, the database with 12 × 1M objects achieves the best query times, while the database with 12 × 2M objects provides nearly identical performance.
RootDB on MySQL: Test Summary
MySQL delivers approximately average performance as a storage platform for RootDB compared to the other systems tested. It achieves a write speed of around 5500 to 8500 objects per second when no indexing is applied or when only value fields are indexed. This level of performance is reasonable and likely adequate for many application scenarios. However, when indexing is extended to include both the object fields used in searches and all relationships within the object model, the write speed drops significantly, with two out of three test cases falling even below 3000 objects per second.
When evaluating the performance of MySQL queries, execution times should be considered in relation to the size and complexity of the database. For example, a cold cache query time of 106 seconds without indexing might seem long in isolation, but for a database containing 24 million objects and multiple many-to-many relationships, it is a reasonable or even impressive result. Most importantly, even with very large databases, there is no risk that the query would fail or crash, even when indexing is not used. At best, a cold cache query time of 9.944 seconds is achieved with full indexing, which is less than one tenth of the result without indexing, and can be considered a very good outcome for a database of this size and complexity with relational structures. For small databases, query times well below one second are achieved for 1.2 million objects, which is already more than sufficient even for interactive applications.
It is also important to emphasize that the query results return complete objects according to the object model. Each root object includes its full data structure, containing all objects that are reachable from it. This level of completeness is a built-in feature of object databases and is difficult to replicate with traditional relational databases and SQL, where such results typically require complex and labor intensive programming.
Overall, MySQL has proven to be a reasonably efficient platform for RootDB object databases. However, its reliability leaves room for improvement, as tests repeatedly revealed that transactions executed concurrently by multiple threads lead to database lock situations. These are reported by the database with error messages such as: "Deadlock found when trying to get lock; try restarting transaction.". The database engine offers no built-in mechanism for recovering from such errors. Instead, it interrupts the transaction and restores the database to its previous state, effectively performing a rollback.
From the perspective of the database programmer, this appears as a random and unpredictable failure without any meaningful explanation. Preparing application logic to handle such sporadic errors is a demanding task, as it may involve restoring the state of many variables in the calling program to what they were before the transaction began. The complexity of reinitializing these variables depends heavily on their role and use within the application.
Building such elaborate safeguards into every transaction leads to an unreasonable increase in program complexity and code volume. This kind of defensive programming cannot be considered a justified or acceptable burden for application developers.
Otherwise, MySQL handles complex object models, including those with many to many relationships, reasonably efficiently, even without indexing when sequential search must be used. MySQL query performance is consistent and scales predictably with the level of indexing and the size of the database, which the query execution algorithms in RootDB are able to utilize effectively. As a result, query times increase approximately in proportion to the size of the database, successfully fulfilling one of the central design goals of RootDB.
Links to other pages on this site.
- Performance Benchmarking on Many-to-Many (M:N) Relationships with Variations in Indexing and Sizes of Object Databases: Performance Comparison: MySQL vs. MariaDB
- Performance Benchmarking on Many-to-Many (M:N) Relationships with Variations in Indexing and Sizes of Object Databases: Performance Comparison: Postgres vs. MariaDB
- Performance Benchmarking on Queries of a New Category with Variations in Indexing and Object Database Sizes
Performance Comparison with Multiple Query Conditions in an Object Hierarchy - Performance Comparison Many-to-Many (M:N) Relationships with Indexing
- Performance Comparison Many-to-Many (M:N) Relationships without Indexing
- RootDB, Technical Features
- RootDB and RQL, Home
Page content © 2025

Contact us:
