Proposal for an Enhanced Definition
of Database Transactions
Atomicity in the ACID properties needs to be extended for object databases
1. Introduction and Motivation
1.1. The Demands of Parallel Computing Call for Automatic Retry Logic
Database application programmers are increasingly confronted with challenges resulting from the growing use of parallel computing to improve performance. Object databases typically manage complex, network like data structures, whose storage and maintenance place significant demands on the internal operation of the database, particularly on the efficiency and concurrency behavior of indexing during parallel transaction execution.
Tests conducted with RootDB using various database products have shown that transactions executed concurrently by multiple threads can frequently lead to deadlock situations. These are reported by the database with error messages such as: "Deadlock found when trying to get lock; try restarting transaction." The database engine offers no built-in mechanism for recovering from such errors. Instead, it interrupts the transaction and restores the database to its earlier state, effectively performing a rollback.
The received deadlock error message clearly indicates that the SQL commands submitted for processing within the transaction were both syntactically and logically correct. However, an internal flaw or limitation in the database engine algorithms leads to a state where the calling application is instructed to retry the transaction. When the transaction is retried, it typically succeeds on the first attempt. Even if multiple attempts are needed, the transaction eventually completes successfully, at least in the many tests performed with RootDB. This confirms that the database is being used correctly and that the fault lies in the internal logic of the database engine. It is also worth noting that these tests involve only the addition of new objects to the database. The new objects may refer to existing ones, but no deletions are performed.
From the perspective of the database programmer, this appears as a random and unpredictable failure without any meaningful explanation. Preparing application logic to handle such sporadic errors is a demanding task, as it may involve restoring the state of many variables in the calling program to what they were before the transaction began. The complexity of reinitializing these variables depends heavily on their role and use within the application.
Building such elaborate safeguards into every transaction leads to an unreasonable increase in program complexity and code volume. This kind of defensive programming cannot be considered a justified or acceptable burden for application developers.
2. The Transaction ACID Properties are Limited to Database Content
2.1. Traditional Definition
The requirement to restart a transaction can also be examined from the perspective of how a transaction is defined. In classical database theory, a transaction is understood as a sequence of operations, typically read and write operations on a database, that together represent a logical unit of work. This unit must satisfy the four well known ACID properties:
- Atomicity : All operations in the transaction are treated as a single unit. They either all succeed or all fail.
- Consistency : A transaction transforms the database from one valid state to another, preserving all database rules and constraints.
- Isolation : Transactions are executed independently. Intermediate states are not visible to other concurrent transactions.
- Durability : Once a transaction is committed, its changes persist, even in the event of a system failure.
2.2. Lack of Object Awareness in ACID Properties
These properties are designed to govern the internal behavior of the database and the changes to its state that occur as operations are executed. They do not define anything about the state of the calling program before or after the transaction, or in the event that the transaction is interrupted and rolled back. This level of definition has traditionally been considered sufficient and aligns well with established relational database programming practices.
However, problems begin to arise as soon as transactions involve the storage of objects in ACID compliant databases. It is also worth noting that objects are stored in databases not only through systems like RootDB, but also by other means such as Object Relational Mapping (ORM) frameworks. The transaction related issues specific to objects are examined below using the object model that is widely used in RootDB testing.
3. RootDB and Its Standard Object Model Context
3.1. Overview of the Object Model
The object model consists of 12 Java classes N1-N4, M1-M4 and S1-S4.
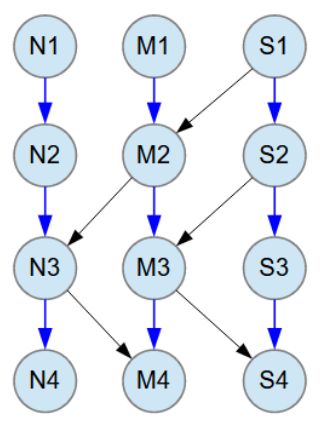
Blue arrow relationships between classes are M:N (many-to-many). All M:N relationships have 1-3 child objects at random.
Black arrow relationships between classes are M:1 (many-to-one).
Below is an excerpt from the code that stores the new M1 objects contained in the m1 array into the RootDB database. The operation is performed within a while loop that continues until a break command at the end of the loop allows the execution to proceed further. Inside the while loop, a try-catch block is used. The try section contains a for loop, which is enclosed in a transaction defined by the rdb.beginTransaction() and rdb.commitTransaction() calls. The transaction guarantees that all objects from the m1 array are stored as a single unit of work. If a failure occurs, no changes are made to the database.
3.2. The Deadlock Exception
In such a case, an exception is thrown at the line rdb.store(m1obj), where the store method communicates with the database. For example, the previously described error "Deadlock found when trying to get lock; try restarting transaction." triggers such an exception, which is then handled in the catch block. It is worth noting that, to keep the source code simple, the catch block is here designed to handle only this specific exception and assumes that no other exceptions will occur.
In addition, the try block includes only a single call to the store method, which stores M1 root class objects in the database. However, it is quite common that a transaction contains even many calls to the store method with multiple different root class types because each of them must be saved by their own store method call. This adds even more complexity to managing recovery in situations where the transaction fails and needs to be restarted.
// Variable rdb represents the opened RootDB object database.
// m1 is an array containing new object instances of the M1 class.
// Each M1 object initially has null as the value of its id field.
while (true) {
try {
rdb.beginTransaction();
for (M1 m1obj : m1) {
rdb.store(m1obj);
}
rdb.commitTransaction();
} catch (Exception e) {
rdb.rollbackTransaction();
continue;
}
break;
}
3.3. Recovery from The Deadlock Exception
The correct way to handle the exception in the catch block may depend on the database product, as different database engines handle rollback operations differently. In some systems, such as MySQL, the transaction is automatically rolled back by the database engine when a deadlock occurs. If the application still calls the ROLLBACK statement after this, the database engine simply ignores it without raising an error. The call to rdb.rollbackTransaction() in the catch block assumes that the underlying engine behaves like MySQL and accepts redundant rollback requests without issue. This allows additional post processing logic to be combined with the rollback handling in a seamless manner, which is particularly useful in the context of object databases.
The need for additional post processing arises from how objects are stored in the database through the call rdb.store(m1obj) within the for loop. The parameter m1obj is a reference to an object of the M1 class. As shown in the object model image above, the M1 class is a root class that consists of a network of related objects from the classes M2, M3, M4, N3, N4, and S4. When an M1 object is passed to the store method, the entire network of objects is stored in the database as a single data structure. The data structure may contain both new and old objects. New objects are added to the database, and old objects are updated.
3.4. Identity Management in New Objects
New objects are particularly significant from the perspective of transactions because they do not have an identity in the database before the transaction begins. When these objects are stored, RootDB generates a unique identity value for each of them, represented as a long integer, and ensures that it is unique across the entire database. This identity value is automatically assigned to the id field of each new object. Initially, all new objects have a null value in their id field. It is important to note that assigning the id value modifies the content of the data structure rooted at the m1obj object passed to the store method.
4. What Must Be Done Before Retrying a Failed Transaction
4.1. Identity Values in New Objects
If a transaction fails, it is likely that some of the new objects have already received an id value in their id fields. After the transaction is interrupted by a deadlock exception, it is essential to reset the assigned id values to null before attempting the retry. Otherwise, the application may attempt to store new objects that incorrectly contain non null id values, which indicate that they are old objects already known to the database. This type of error is critical because it corrupts the internal consistency of the object structure and makes it unusable with the database.
4.2. Id Values, Artificial Identity, in Relational Databases
A similar requirement to reset id values to null generally does not arise in relational databases, as they are traditionally programmed using the SQL command language. Uniquely generated id values, known as artificial identity keys, are also widely used in these systems to assign an identity to a single row in a table, commonly referred to as a record. In the application using the database, this record may correspond to a programming language construct such as a record or an object, where their definitions include fields that map directly to the columns of a database table. In other words, the id is typically implemented as a field of the record or object.
4.3. SQL Record Commands vs Object Database Methods
In relational databases, records are inserted, updated, and deleted using SQL commands, each of which performs only one type of operation. These commands are INSERT, UPDATE, and DELETE, and their names clearly indicate their specific function. In contrast, in an object database, the store method processes an entire data structure in a single call of the store method. This structure may contain both new and old objects. New objects are added to the database and assigned identity values, while old objects are identified based on their existing id values and updated. As a final step, the store method performs garbage collection, which automatically removes objects that are no longer needed.
4.4. Resetting Identity Fields Manually in Relational Databases
In object databases, a single call to the store method may therefore result in multiple insert, update, and delete operations. In relational database programming, these three types of data manipulation are typically separated into three methods such as save, update, and delete. Of these, only the save method might assign database generated identity values to the records or objects. Furthermore, the save method can be implemented so that the id values of the records or objects are not passed in the generated SQL command, since the database always generates new identity values. These values are then written into the id fields of the saved records or objects, regardless of whether the fields already contained a non null value.
4.5. Resetting Identity Fields Manually in Object Databases
This traditional model of relational database programming helps explain why the current ACID based definition of transactions is generally sufficient. In contrast, the programming model of object databases, where all data modifications including inserts, updates, and deletions are performed in a single call, illustrates why requiring the programmer to manually reset id values to null before restarting a transaction can be considered an unreasonable burden. The complexity of this task is demonstrated in the example below, where the earlier code excerpt that stores new M1 objects from the m1 array into the RootDB database is modified so that it manages the resetting of null id values for new objects on its own.
// Variable rdb represents the opened RootDB object database.
// m1 is an array containing new object instances of the M1 class.
// Each M1 object initially has null as the value of its id field.
while (true) {
try {
rdb.beginTransaction();
for (M1 m1obj : m1) {
rdb.store(m1obj);
}
rdb.commitTransaction();
} catch (Exception e) {
rdb.rollbackTransaction();
for (M1 m1obj : m1) {
m1obj.id = null;
resetRelatedNewObjects(m1obj);
}
continue;
}
break;
}
In the catch block of the try catch structure, the transaction is first rolled back. Then, a for loop iterates through each M1 object in the m1 array to reset the id values of both the object itself and its related new objects. The id field of the loop variable m1obj is set to null unconditionally, since it is known to be a new M1 object. Overwriting an existing null value has no effect. However, resetting the id values of related new objects is significantly more complex and is delegated to the method call resetRelatedNewObjects(m1obj).
4.6. The Complexity of Resetting ID Values in Related New Objects
Inside this method, the data structure rooted at m1obj must first be traversed, because there is no straightforward way to identify the related new objects directly. Moreover, not every object with a non null id value is necessarily a new object. Some may already exist in the database. Therefore, all found objects with a non null id must be checked against the database, and only those not found are classified as new objects whose id fields must be reset to null.
This is the core logic that resetRelatedNewObjects must implement. However, its actual implementation is omitted here because it would be cumbersome, inefficient, and impractical in real use. The implementation would need to traverse the data structures of all root class objects used in the store method calls and reset the id values of their new objects to null. In the example above, only a single root class M1 is used, but in general, store may be called for objects of many different root class types within the same transaction.
4.7. An Object Model–Specific Algorithm for Resetting Identities
Although the programmer has access to the Java classes of the object model, the amount of work can still be considerable, especially when accounting for all possible relationship types and potential recursion. An alternative approach is to write a general-purpose program that navigates data structures using reflection. However, this cannot be considered a viable solution for an ordinary programmer who simply wants to use databases without delving into generic programming of data structures.
4.8. A General Reflection-Based Approach to Resetting Identities
Moreover, reflection is widely known to be poorly suited for handling large volumes of data, as it adds a relatively heavy layer to the implementation, and its runtime performance is especially poor. It is also worth emphasizing that such complex logic would be required for almost every transaction that modifies the content of an object database, placing a significant and unnecessary burden on application developers.
5. The Extended Definition of Atomicity
5.1. Reexamining the Atomicity Property
For the reasons described above, it would be beneficial to extend the definition of the ACID properties, especially the Atomicity property, to better address the needs of object databases. The ACID properties required of a transaction have already been listed above. For clarity, the definition of the Atomicity property is repeated here to highlight the specific point in the ACID definition where its extension is proposed:
- Atomicity : All operations in the transaction are treated as a single unit. They either all succeed or all fail.
While this formulation is generally sufficient for relational databases, it does not fully address the specific requirements introduced by object databases. In particular, it fails to account for the preservation of object identities within the data structures being manipulated. When a transaction involving object storage fails, any newly assigned identity values, such as object ID values, must be reverted to their original uninitialized state to maintain semantic integrity. Failure to do so may result in corrupted object structures and inconsistent database interaction.
5.2. Proposal to Extend the Definition of Atomicity
For the reasons outlined above, an extended definition of Atomicity is presented here to incorporate and support the identity semantics of object-oriented data models. The addition to the traditional definition is highlighted in red below:
- Atomicity (extended) : All operations in the transaction are treated as a single unit. They either all succeed or all fail. If the transaction fails, any new objects assigned an identity during the transaction must have their identities restored.
Restoring the identities of new objects refers to returning them to a state where they are no longer recognized as having been previously stored in the database. In many implementations, this means setting identity fields to null, but the exact mechanism depends on how identity is represented in the object model. In some cases, identity may be derived from a combination of fields or managed by internal metadata flags. The core requirement is that, after a failed transaction, all new objects must behave as if they had never been assigned an identity, thereby ensuring they will be correctly processed as new objects when the transaction is retried
6. RootDB as Reference Implementation
6.1. Transactions Designed to Respect Object-Oriented Identity Semantics
RootDB can be seen as a kind of reference implementation for object databases, as it provides a broad range of entirely new features that elevate the abstraction level of database programming from records to modern programming objects and their associated dynamic data structures. Its design and implementation also take into account the possibility of needing to restart a transaction, along with the extended definition of the Atomicity property, which includes restoring null values to new objects, as proposed above.
6.2. Transaction Commit and Rollback Have Direct Access to Newly Stored Objects
In practice, when the store method is executed, it passes information about the newly stored objects to the transaction, which collects them until the transaction is completed using either a commit or rollback operation. If the transaction succeeds, it is finalized by calling rdb.commitTransaction(), which sends a request to the database to perform the commit and then clears the transaction’s collection of the newly stored objects.
In the case of transaction failure, rollback is initiated by calling rdb.rollbackTransaction(), as shown in the catch block of the first code example, which prepares for potential deadlock exceptions. This call requests the database to execute the rollback operation. After that, it resets the id fields of all newly stored objects back to null, based on the internal collection maintained by the transaction before it was interrupted. Both root objects passed as parameters in store method calls and their related new objects in their data structures are included, provided a new id value has already been assigned to them. It is important to note that the store method is also used to update an existing root object and its associated data structure in the database. In such cases, the root object itself already has an id, so the automatic reset operation applies only to new objects within its data structure that received id values during the transaction. This fulfills the extended Atomicity definition, which requires that the state of new objects be preserved after the interruption of the transaction.
6.3. Minimal Overhead with Extended Atomicity
It is important to note that implementing the extended Atomicity property requires only a small addition to the algorithms of the store method. In practice, this has virtually no effect on the method’s runtime performance.
7. Encouraging Database Experts to Elevate Conceptual Thinking Beyond Relational Models
7.1. Relational Databases Remain Unchanged Under the Extended Atomicity Definition
Relational database experts may view the proposed minor revision to the Atomicity property as a significant conceptual shift, perhaps even crossing a fundamental boundary in database theory. This reaction stems from their focus on relational databases and the traditional record-based programming models using the SQL command language. In that context, modifying the ACID definition to support objects is clearly unnecessary. Moreover, the revised definition would have no practical effect on such systems, as they do not involve objects.
7.2. Extending Atomicity Beyond Database Content May Face Resistance
However, the proposal to extend Atomicity property represents a significant conceptual decision and may trigger resistance, since the current ACID definition applies exclusively to the state of the database. It defines how the database must remain unchanged if a transaction fails and is rolled back. The proposed extension introduces a new requirement: the identity of new objects must also be restored within the application using the database, thereby clearly extending the scope of the ACID definition to include the application side as well.
7.3. No Cause for Concern: Implementation of Extended Atomicity Is Internal to the Database Engine
Although this introduces a clear and arguably demanding requirement to restore object identities in the application, it is important to emphasize that the responsibility does not fall on the application programmer. Instead, it belongs to the provider of the object database system. RootDB is a pioneer in this respect, demonstrating with its own implementation that the extended Atomicity property can be incorporated easily, seamlessly, and with excellent runtime efficiency.
This should also be reassuring to relational database experts, since the implementation of the extended ACID properties remains entirely within the database engine and does not impose any additional burden on application developers. On the contrary, it offers them a more intuitive and reliable interface to the database, including automatic recovery from transaction failures caused by deadlocks. This is a significant and meaningful advancement, one that database experts may be expected to recognize, support, and even promote in future systems.
8. Conclusion: Extending Atomicity to Support Object Identity Semantics
8.1. Transaction Failures Reveal a Critical Gap in the ACID Model
In database transaction programming, it is not uncommon to encounter situations where an otherwise correct SQL statement results in an error message instructing the program to retry the transaction. This indicates that an internal error has occurred in the database engine, typically due to simultaneous execution of multiple transactions that happen to conflict. These are not necessarily the result of multiple applications accessing the same database concurrently because even a single application, running multiple threads in parallel, can place enough load on the database to cause such errors.
The rise of parallel computing in database applications has naturally increased the frequency of these kinds of concurrency related failures. For reasons that remain unclear, database vendors have not fully addressed these issues within their engines. Instead, they place the burden on application developers by instructing them to catch such errors and simply retry the transaction. A typical example is the well known MySQL error message:
"Deadlock found when trying to get lock; try restarting transaction."
This message clearly indicates that a deadlock occurred within the MySQL database due to concurrent thread execution and that the database engine itself cannot resolve it. The responsibility is therefore passed to the application, which must detect the failure and rerun the transaction. As a result, shortcomings in database engine design propagate into the application layer, where otherwise unnecessary code is now required to handle sporadic retry logic. This forces developers to introduce complex and error-prone program structures into nearly all database programming. It could be argued that these unreliable behaviors in database systems impose needlessly complex and messy programming models on applications, leading to increased costs in both development and long-term maintenance.
Retrying a transaction is rarely as simple as placing the transaction logic in a while loop and rerunning it until it succeeds. Most transactions rely on program variables and data structures that may have changed during the failed transaction's execution. These must be restored to their original state before retrying. This challenge becomes especially problematic in modern object databases like RootDB, and even in mature ORM systems like Hibernate.
In RootDB, object identity is assigned using a numeric ID fetched from the database. Objects are stored via a single call to the store method, which takes only the root object of the data structure as a parameter. This structure may include both new and old objects. New objects are recognized by the fact that they lack an assigned identity. When a transaction fails, say due to a deadlock in the database engine, it is possible that some new objects have already been assigned IDs. In this case, retrying the transaction becomes difficult because these already updated objects must first be located and reset to their original uninitialized state. Identifying and resetting them within the root object’s data structure is not only technically complex, but also places an unreasonable burden on application developers, who should not be expected to implement such low level recovery logic.
8.2. Object-Aware Atomicity Enables Seamless Recovery
A far better solution is to shift this responsibility to the database engine itself by extending the semantics of transactions to incorporate the necessary low level recovery logic. Traditionally, a transaction is defined as a sequence of operations, usually reads and writes, that together represent a logical unit of work. This unit must satisfy the four well known ACID properties. We propose a modest extension to the Atomicity property to ensure that the identities of new objects are also restored to their original state in the event of a failure.
The revised definition of Atomicity is shown below. The added requirement, relevant only to object oriented databases, is highlighted in red:
- Atomicity : All operations in the transaction are treated as a single unit. They either all succeed or all fail. If the transaction fails, any new objects assigned an identity during the transaction must have their identities restored.
- Consistency : A transaction transforms the database from one valid state to another, preserving all database rules and constraints.
- Isolation : Transactions are executed independently. Intermediate states are not visible to other concurrent transactions.
- Durability : Once a transaction is committed, its changes persist, even in the event of a system failure.
RootDB transactions conform to this revised definition of the ACID model. As a result, retrying a transaction becomes effortless because RootDB automatically resets the id values of any new objects to null if they had already been assigned identities before the transaction failed. For example, consider the following simplified code. Here, any exception is interpreted as grounds for retrying the transaction:
// Variable rdb represents the opened RootDB object database.
// m1 is an array containing new object instances of the M1 class.
// Each M1 object initially has null as the value of its id field.
while (true) {
try {
rdb.beginTransaction();
for (M1 m1obj : m1) {
rdb.store(m1obj);
}
rdb.commitTransaction();
} catch (Exception e) {
rdb.rollbackTransaction();
continue;
}
break;
}
All exceptions are handled in the catch block. First, the rollbackTransaction() method is called, which instructs the database to roll back any partial changes. Immediately afterward, RootDB automatically resets the id fields of any new objects that had already been assigned an identity. This restores the application state to what it was before the failed transaction began.
This approach eliminates the need for complex low level recovery logic and prevents developers from being burdened simply because the database engine encounters random concurrency errors. In effect, it realizes what was earlier described as a straightforward but inadequate solution: placing the transaction logic inside a simple while loop and repeating it until the transaction succeeds. This marks a significant achievement that fully justifies the proposed object aware extension to the ACID model.
8.3. A Backward-Compatible Refinement with Future Impact
The proposed extended definition of the Atomicity property in the ACID model does not discard or weaken existing database theory. It is fully backward compatible because it has no effect on relational databases, which do not work with objects and therefore remain unaffected by this refinement. Its advantages become evident in modern object databases like RootDB and may also play a role in the continued evolution of traditional ORM systems such as Hibernate. This small but essential enhancement to the ACID model is designed to support the emergence of truly robust object aware database systems in the near future.
Links to other pages on this site.
- Performance Benchmarking on Many-to-Many (M:N) Relationships with Variations in Indexing and Sizes of Object Databases: Performance Comparison: MySQL vs. MariaDB
- Performance Benchmarking on Many-to-Many (M:N) Relationships with Variations in Indexing and Sizes of Object Databases: Performance Comparison: Postgres vs. MariaDB
- Performance Benchmarking on Queries of a New Category with Variations in Indexing and Object Database Sizes
Performance Comparison with Multiple Query Conditions in an Object Hierarchy - Performance Comparison Many-to-Many (M:N) Relationships with Indexing
- Performance Comparison Many-to-Many (M:N) Relationships without Indexing
- RootDB, Technical Features
- RootDB and RQL, Home
Page content © 2025

Contact us:
